All our software connects Jira & Confluence with Microsoft 365. We use almost the same data flows independently of the hosting option.
So Jira Cloud, Jira Server and Jira Data Center roughly works the same, sharing the same data storage and processing guidelines.
Data Storage
We only store content that has been explicitly created by our apps. The exact data varies by used features.
But overall the app stores the following data:
In general there is an enforced guideline that we do not store Jira content (like Jira issues, comments, etc.) or Microsoft content (like chat or mail content) on our servers.
Data Processing
We process data from your Jira, Microsoft 365 as well as our own data in our infrastructure. The following diagram details the data-flow.
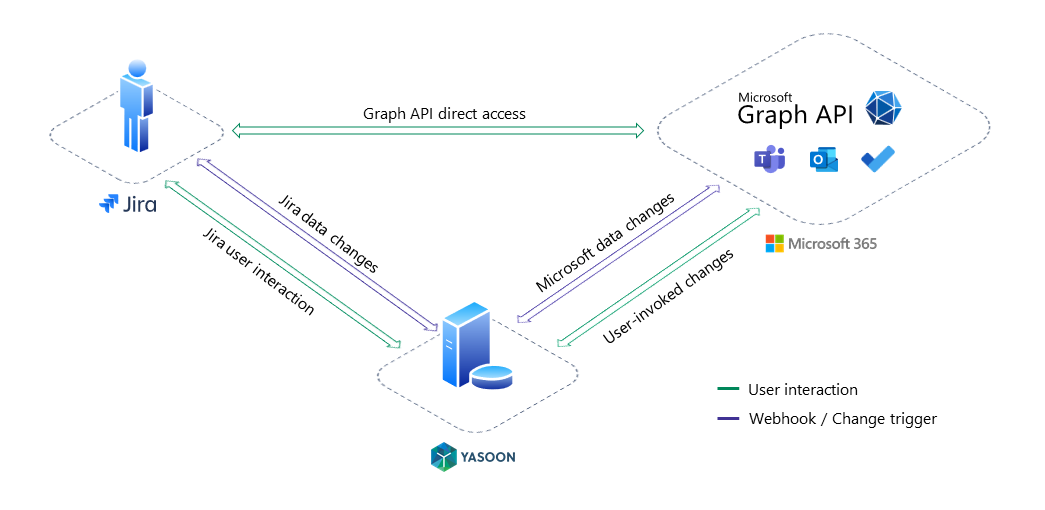
Overall, all data that are shown to the user by our app could be processed on our servers.
Data processing can occur in two different ways, read below.
1. User interactions
Whenever a user is interacting with one of our features (in Jira , Confluence, Outlook addin or Teams app) we process data to fulfill the request. Mostly, this includes the current business context (e.g. issue, page, email, Teams chat), but also includes users email addresses.
2. Application triggered changes (webhooks)
Some features are triggered without user interaction, but are triggered via webhooks to be processed.
We get notified on the following events, if the feature is activated and used:
-
Issue creation or update
-
Emails received
-
New meetings
-
Todo updated
Limits on data flow
Whenever we implement a new feature which requires data flowing through our system, we strive to limit this as much as possible. We balance the usability of a feature with the amount of involved data, but we will never crawl all your Microsoft 365 or Atlassian data and / or store private content in our database.
Exceptions
There is a legacy exception for customers using only the Outlook add-in for Jira Server/Data Center that runs locally only. Going forward, with our core focus on integrating with Microsoft 365, new features will require connectivity with our own service.